Deep learning tooling¶
A simple deep learning pipeline for remote sensing with PyTorch Lightning and MLFlow
Using deep neural networks for remote sensing applications often involves a complex pipeline including data processing, model definition, training and evaluation. Moreover, multiple training runs are launched for each experiment made, and the history of all the models trained is often hard to recover. This tutorial shows how to use classical tools like PyTorch Lightning and MLFlow to facilitate the training of deep learning models in a remote sensing context. Our model will process Sentinel-2 RGB images and predict the NIR band of these images.
Imports from AI4GEO VRE¶
The AI4GEO VRE provides all the deep learning frameworks needed to design and train deep models: specifically PyTorch and PyTorch Lightning which will be used in this tutorial. Packages needed to read and transform satellite images are also available (rasterio, numpy)
Note: MLFlow is not part of the VRE yet
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import os
import numpy as np
import rasterio
from tqdm.notebook import tqdm
import pytorch_lightning as pl
import mlflow
import optuna
Definition of the dataset¶
The first step is to create a dataset class to load our images and transform them into arrays that can be handled by our deep learning framework. Datasets can be configured to read all the images from the beginning (time efficient, load the images in the init method) or read the images only when needed (memory efficient, load the images in the getitem method). Because our dataset is less than 1Go, we choose to load all the images in RAM from the beginning, to save accessing time during training. With a much larger dataset (> 10Go), it would have been better to use the memory efficient method.
class SentinelDatasetRGB2NIR(Dataset):
def __init__(self, subset, data_dir):
im_dir = os.path.join(data_dir, subset)
f_list = os.listdir(im_dir)
im_paths = [os.path.join(im_dir, f_name) for f_name in f_list]
print("Loading {} dataset in RAM...".format(subset))
self.rgb_images = []
self.nir_images = []
for im_path in tqdm(im_paths, total=len(f_list)):
im = rasterio.open(im_path).read().astype(np.float32)
rgb = im[:, :, :256]
nir = im[:, :, 256:]
self.rgb_images.append(rgb)
self.nir_images.append(nir)
print("Dataset loaded")
def __getitem__(self, i):
rgb = self.rgb_images[i]
nir = self.nir_images[i]
return rgb, nir
def __len__(self):
return len(self.rgb_images)
Definition of the model and the training pipeline¶
Lightning module documentation: https://pytorch-lightning.readthedocs.io/en/stable/common/lightning_module.html
PyTorch Lightning provides a class to define the architecture on the model. The methods __init__() and forward are similar to PyTorch, but PyTorch Lightning provides additional methods to define the training and validation pipeline. These method will be called at each batch for training step and validation step respectively. This is inside these methodes where we can log the metrics of each batch to our logger. There is two possible methods:
Using the logger of the PyToch Lightning module¶
The logger is integrated to PyTorch Lightning "Trainer" class. By default Tensorboard logger is integrated but it is possible to define MLFlow as the logger (cf. Training loop). Loggers supported by PyTorch Lightning are:
- Tensorboard
- MLFlow
- Weight & Biases
- Neptune.ai
- Comet.ml
PyTorch Lightning loggers documentation: https://pytorch-lightning.readthedocs.io/en/stable/extensions/logging.html
In this case, the logger of our module is Tensorboard. To log metrics to Tensorboard, we simply need to call the log method of the module (self.log, cf. training_step() in this chunk).
Pros: Simple to use for basic funtionalities, no additional dependancies
Cons: Advanced functionalities of the logging module are harder to use / unavailable (ex: logging images in tensorboard, logging models in MLFlow)
Using our logger outside of PyTorch Lightning¶
It is also possible to use the Python package of our logger independantly of PyTorch Lightning. We have to import the package and call functions specific to that package to log metrics.
In this case, we imported mlflow package and then we can use mlflow.log_metric function the same way we use self.log
Warning: mlflow.log_metric cannot take Torch Tensors as input so the loss has to be casted to Python float.
class ConvNetRGB2NIR(pl.LightningModule):
def __init__(self, lr, n_chan, batch_size, improved_encoder, improved_decoder, loss, **kwargs):
super().__init__()
self.conv1a = nn.Sequential(nn.Conv2d(3, n_chan, kernel_size=3, stride=2, padding=1), nn.ReLU())
self.conv1b = nn.Sequential(nn.Conv2d(n_chan, n_chan, kernel_size=3, padding=1), nn.ReLU())
self.conv2a = nn.Sequential(nn.Conv2d(n_chan, 2*n_chan, kernel_size=3, stride=2, padding=1), nn.ReLU())
self.conv2b = nn.Sequential(nn.Conv2d(2*n_chan, 2*n_chan, kernel_size=3, padding=1), nn.ReLU())
self.conv3a = nn.Sequential(nn.Conv2d(2*n_chan, 4*n_chan, kernel_size=3, stride=2, padding=1), nn.ReLU())
self.conv3b = nn.Sequential(nn.Conv2d(4*n_chan, 4*n_chan, kernel_size=3, padding=1), nn.ReLU())
self.deconv3a = nn.Sequential(nn.ConvTranspose2d(4*n_chan, 2*n_chan, kernel_size=4, stride=2, padding=1), nn.ReLU())
self.deconv3b = nn.Sequential(nn.Conv2d(4*n_chan, 2*n_chan, kernel_size=3, padding=1), nn.ReLU())
self.deconv2a = nn.Sequential(nn.ConvTranspose2d(2*n_chan, n_chan, kernel_size=4, stride=2, padding=1), nn.ReLU())
self.deconv2b = nn.Sequential(nn.Conv2d(2*n_chan, n_chan, kernel_size=3, padding=1), nn.ReLU())
self.deconv1 = nn.Sequential(nn.ConvTranspose2d(n_chan, 1, kernel_size=4, stride=2, padding=1), nn.ReLU())
if loss == "l1":
self.loss = nn.L1Loss()
elif loss == "smooth_l1":
self.loss = nn.SmoothL1Loss()
else:
raise ValueError("Loss {} unknown".format(loss))
self.save_hyperparameters() #save arguments of __init__() into self.hparams attribute
def forward(self, x):
layer1 = self.conv1a(x)
if self.hparams.improved_encoder:
layer1 = self.conv1b(layer1)
layer2 = self.conv2a(layer1)
if self.hparams.improved_encoder:
layer2 = self.conv2b(layer2)
layer3 = self.conv3a(layer2)
if self.hparams.improved_encoder:
layer3 = self.conv3b(layer3)
layer4 = self.deconv3a(layer3)
if self.hparams.improved_decoder:
layer4_2 = torch.cat((layer4, layer2), axis=1)
layer4 = self.deconv3b(layer4_2)
layer5 = self.deconv2a(layer4)
if self.hparams.improved_decoder:
layer5_1 = torch.cat((layer5, layer1), axis=1)
layer5 = self.deconv2b(layer5_1)
layer6 = self.deconv1(layer5)
return layer6
def training_step(self, batch, batch_idx):
x, y = batch
pred = self(x).repeat(1,3,1,1)
loss = F.l1_loss(pred, y)
self.log("train_loss", loss)
mlflow.log_metric("train_loss", float(loss.cpu()))
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
pred = self(x).repeat(1,3,1,1)
loss = F.l1_loss(pred, y)
psnr = 10*torch.log(torch.max(y)**2/F.mse_loss(pred, y))
self.log("val_loss", loss)
self.log("val_psnr", psnr)
mlflow.log_metric("val_loss", float(loss.cpu()))
mlflow.log_metric("val_psnr", float(psnr.cpu()))
#Log images in tensorboard
rgb = torch.clamp(x[0], max=1)
real_nir = y[0]
fake_nir = pred[0]
image = torch.cat((rgb, real_nir, fake_nir), dim=2)
self.logger.experiment.add_image("RGB-NIR_{}".format(batch_idx), image, self.current_epoch)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.hparams.lr)
return optimizer
Definition of the DataModule to encapsulate datasets and dataloaders (optional)¶
PyTorch Lightning provides an additional class to encapsulate initialisation of datasets and connections between dataloaders and datasets. The chunk below provides a minimal definition of a datamodule for our problem
class SentinelDataModuleRGB2NIR(pl.LightningDataModule):
def __init__(self, data_dir, batch_size):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
def setup(self, stage=None):
self.train_dataset = SentinelDatasetRGB2NIR("train", self.data_dir)
self.val_dataset = SentinelDatasetRGB2NIR("valid", self.data_dir)
def train_dataloader(self):
return DataLoader(self.train_dataset, num_workers=0, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.val_dataset, num_workers=0, batch_size=16, shuffle=False)
Sample hyperparameters with optuna and initialise loggers¶
All the PyTorch Lightning are now initialised, we can then use them to run a training loop. This is also where hyperparamers will be defined. We use optuna to encapsulate the choice of hyperparameters, initialisation of model with these hyperparameters and the launch of the training loop with PyTorch Lightning "Trainer" object. Several hyperparameters will be sampled within a set or range defined by user. Optuna provides several sampling methods which will define how the hyperparameters will be chosen according to the results of the previous trials. We can then give all the hyperparameters to the PL module to desi
This is also where the loggers are initialised. Here we use Tensorboard as the Pytorch Lightning default logger and MLFlow as an external logger.
Initialisation of a PyTorch Lightning logger¶
By default, PyTorch Lightning (PL) use a tensorboard logger which can be used in the PL Module with the self.log method. The name of the experiment will be "default". It is possible to define a custom PL logger as in the chunk below. We can chose the logging framework (here it is TensoBoard), the name of the experiment, the storage path of the logs and other framework-specific argument. Then the logger can be given to the PL Trainer as an argument. It is also possible to use it directly with the methods log_hyperparams or log_metrics
Initialisation of MLFlow as an external logger¶
To use a logger outside of PyTorch Lightning, the instructions are specific to the framework used. We can refer to the MLFlow documentation in our case: https://www.mlflow.org/docs/latest/tracking.html#logging-data-to-runs
Similarly to TensorBoard we can choose the storage path of the logs. It is possible to use a simple directory but we choose to use a SQLite database because it allows more logging functionalities. MLFlow use URI to identify directories or databases to use for storage. By setting the tracking URI to our SQLite database, all metrics and parameters of our modls will be store in this database. However, the artifacts (larger files like models) will be stored in a directory (called mlruns/ by default).
As with TensorBoard we can organise our runs in an experiment, and log the hyperparameters specific to the run. In addition, it is possible to log the resulting model as an artifact. This functionality is not supported by TensorBoard.
def objective(trial):
lr = trial.suggest_float("lr", 2e-4, 8e-4)
n_chan = trial.suggest_int("n_chan", 4, 128, log=True)
batch_size = 8
improved_encoder = trial.suggest_categorical("improved_encoder", [True, False])
improved_decoder = trial.suggest_categorical("improved_decoder", [True, False])
loss = trial.suggest_categorical("loss", ["l1", "smooth_l1"])
max_epochs = 2
hparams = {"lr": lr,
"n_chan": n_chan,
"batch_size": batch_size,
"improved_encoder": improved_encoder,
"improved_decoder": improved_decoder,
"loss": loss,
"max_epochs": max_epochs
}
model = ConvNetRGB2NIR(**hparams)
datamodule = SentinelDataModuleRGB2NIR(data_dir="/home/ai4geo/demo/mlflow-demo/data/Sentinel2-RGB2NIR", batch_size=batch_size)
tensorboard = pl.loggers.TensorBoardLogger("/home/ai4geo/tensorboard_logs", name="optuna_randomsampler", default_hp_metric=False)
trainer = pl.Trainer(max_epochs=max_epochs,
log_every_n_steps=4,
logger=tensorboard,
callbacks=[pl.callbacks.RichProgressBar()]) # rich is used because of display bugs with tqdm.notebook progress bar
tensorboard.log_hyperparams(hparams, {"val_loss": 0, "val_psnr": 0})
# Select the database or directory where metrics and parameters are stored
mlflow.set_tracking_uri(f"sqlite:///{os.environ['MLFLOW_DB']}")
# Select an experiment or create it if it does not exist
experiment_name = "optuna_randomsampler"
experiment = mlflow.get_experiment_by_name(experiment_name)
exp_id = experiment.experiment_id if experiment else mlflow.create_experiment(
experiment_name,
artifact_location=os.environ["MLFLOW_ARTIFACTS_ROOT"]
)
with mlflow.start_run(experiment_id=exp_id):
mlflow.log_params(hparams)
trainer.fit(model, datamodule)
val_loss = trainer.callback_metrics["val_loss"].item()
delattr(model, "trainer") # work-around to avoid pickling error caused by RichProgressBar callback when saving the model
mlflow.pytorch.log_model(model, artifact_path="SimpleCNN", registered_model_name="SimpleCNN4rgb2nir")
return val_loss
Launch the runs with optuna¶
We can finally launch the training with optuna and choose the sampling method for the hyperparameters. It is possible to simply launch one trial (one training) with random hyperparameters as below.
study = optuna.create_study(sampler=optuna.samplers.RandomSampler())
study.optimize(objective, n_trials=2)
[I 2022-05-10 12:05:58,297] A new study created in memory with name: no-name-47d87eec-6a3a-46ea-870b-ac593bac1baf
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Loading train dataset in RAM...
0%| | 0/172 [00:00<?, ?it/s]
/usr/local/lib/python3.8/dist-packages/rasterio/__init__.py:220: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix be returned. s = DatasetReader(path, driver=driver, sharing=sharing, **kwargs)
Dataset loaded Loading valid dataset in RAM...
0%| | 0/24 [00:00<?, ?it/s]
Dataset loaded
┏━━━━┳━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ ┡━━━━╇━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━┩ │ 0 │ conv1a │ Sequential │ 1.9 K │ │ 1 │ conv1b │ Sequential │ 40.5 K │ │ 2 │ conv2a │ Sequential │ 80.9 K │ │ 3 │ conv2b │ Sequential │ 161 K │ │ 4 │ conv3a │ Sequential │ 323 K │ │ 5 │ conv3b │ Sequential │ 646 K │ │ 6 │ deconv3a │ Sequential │ 574 K │ │ 7 │ deconv3b │ Sequential │ 323 K │ │ 8 │ deconv2a │ Sequential │ 143 K │ │ 9 │ deconv2b │ Sequential │ 80.9 K │ │ 10 │ deconv1 │ Sequential │ 1.1 K │ │ 11 │ loss │ L1Loss │ 0 │ └────┴──────────┴────────────┴────────┘
Trainable params: 2.4 M Non-trainable params: 0 Total params: 2.4 M Total estimated model params size (MB): 9
Output()
/usr/local/lib/python3.8/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py :240: PossibleUserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance. rank_zero_warn(
/usr/local/lib/python3.8/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py :240: PossibleUserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance. rank_zero_warn(
/usr/local/lib/python3.8/dist-packages/_distutils_hack/__init__.py:30: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
Registered model 'SimpleCNN4rgb2nir' already exists. Creating a new version of this model...
2022/05/10 12:08:41 INFO mlflow.tracking._model_registry.client: Waiting up to 300 seconds for model version to finish creation. Model name: SimpleCNN4rgb2nir, version 33
Created version '33' of model 'SimpleCNN4rgb2nir'.
[I 2022-05-10 12:08:41,589] Trial 0 finished with value: 0.4265408515930176 and parameters: {'lr': 0.000584160269525476, 'n_chan': 67, 'improved_encoder': True, 'improved_decoder': True, 'loss': 'l1'}. Best is trial 0 with value: 0.4265408515930176.
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Loading train dataset in RAM...
0%| | 0/172 [00:00<?, ?it/s]
/usr/local/lib/python3.8/dist-packages/rasterio/__init__.py:220: NotGeoreferencedWarning: Dataset has no geotransform, gcps, or rpcs. The identity matrix be returned. s = DatasetReader(path, driver=driver, sharing=sharing, **kwargs)
Dataset loaded Loading valid dataset in RAM...
0%| | 0/24 [00:00<?, ?it/s]
Dataset loaded
┏━━━━┳━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ ┡━━━━╇━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━┩ │ 0 │ conv1a │ Sequential │ 2.2 K │ │ 1 │ conv1b │ Sequential │ 57.7 K │ │ 2 │ conv2a │ Sequential │ 115 K │ │ 3 │ conv2b │ Sequential │ 230 K │ │ 4 │ conv3a │ Sequential │ 461 K │ │ 5 │ conv3b │ Sequential │ 921 K │ │ 6 │ deconv3a │ Sequential │ 819 K │ │ 7 │ deconv3b │ Sequential │ 460 K │ │ 8 │ deconv2a │ Sequential │ 204 K │ │ 9 │ deconv2b │ Sequential │ 115 K │ │ 10 │ deconv1 │ Sequential │ 1.3 K │ │ 11 │ loss │ SmoothL1Loss │ 0 │ └────┴──────────┴──────────────┴────────┘
Trainable params: 3.4 M Non-trainable params: 0 Total params: 3.4 M Total estimated model params size (MB): 13
Output()
/usr/local/lib/python3.8/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py :240: PossibleUserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance. rank_zero_warn(
/usr/local/lib/python3.8/dist-packages/pytorch_lightning/trainer/connectors/data_connector.py :240: PossibleUserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance. rank_zero_warn(
Registered model 'SimpleCNN4rgb2nir' already exists. Creating a new version of this model...
2022/05/10 12:11:51 INFO mlflow.tracking._model_registry.client: Waiting up to 300 seconds for model version to finish creation. Model name: SimpleCNN4rgb2nir, version 34
Created version '34' of model 'SimpleCNN4rgb2nir'.
[I 2022-05-10 12:11:51,380] Trial 1 finished with value: 0.35383450984954834 and parameters: {'lr': 0.00035869536009840836, 'n_chan': 80, 'improved_encoder': True, 'improved_decoder': True, 'loss': 'smooth_l1'}. Best is trial 1 with value: 0.35383450984954834.
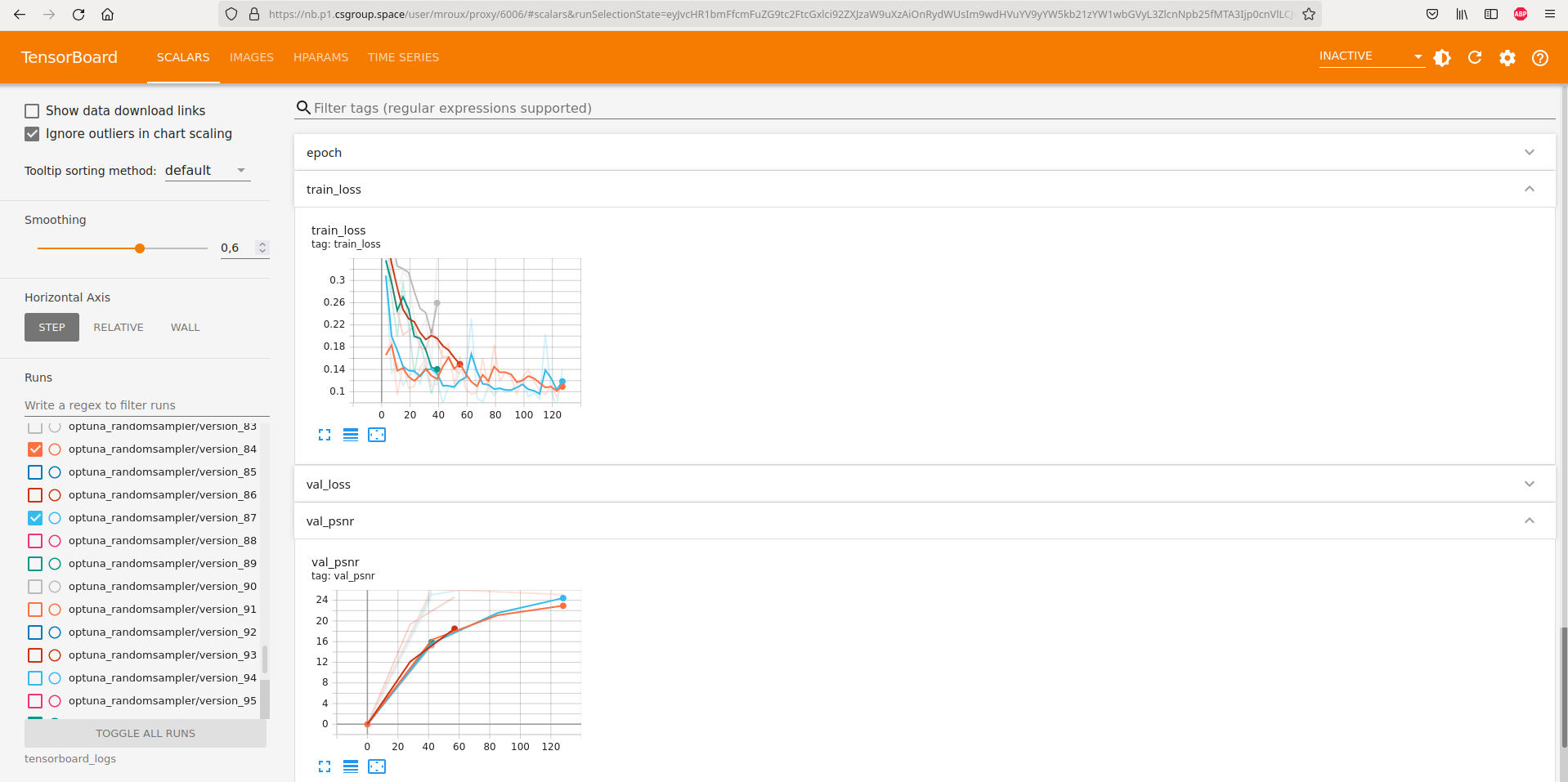
Track and visualize the results¶
During a training, logs are stored on directories or databases. Logging frameworks offer an UI to visualise the results on a web browser.
Launch the Tensorboard UI¶
Open a terminal from JupyterLab, go to the current directory and type:
tensorboard --logdir=/home/ai4geo/tensorboard_logs
Then the server is accessible from https://nb.p1.csgroup.space/user/login/proxy/6006/
An example of logs results visualized in the UI is shown below